We may consider the results to be negative, with respect to selection for differentiation. It turns out that an undifferentiated algorithm with a random dispersal strategy is quite effective, and survives preferentially over the more complex algorithms that attempt to use a differentiated CPU thread to identify the nodes with a higher ratio of Speed/NumCells.
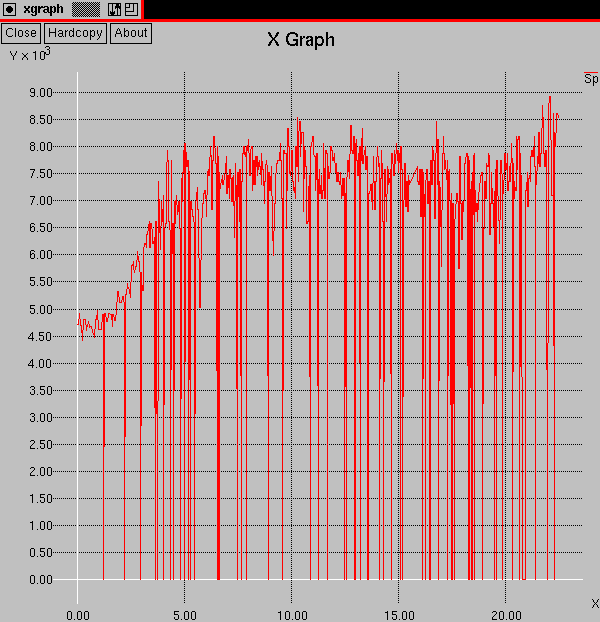
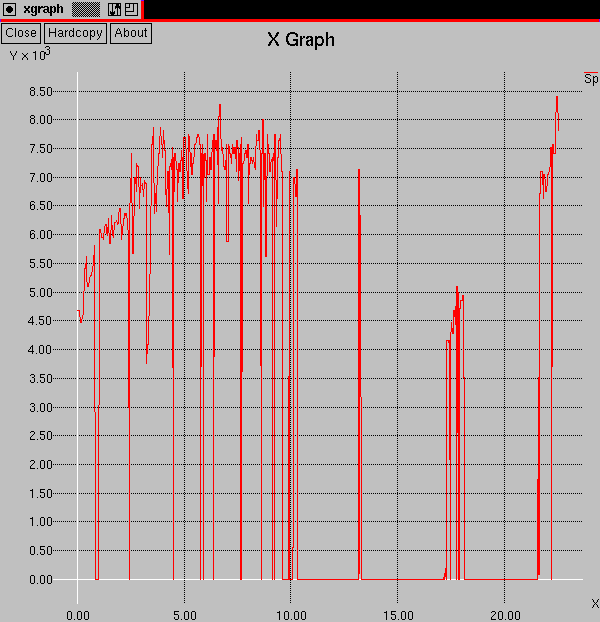
It seems likely that our seed algorithm is not adequate for the task of maintaining itself and its offspring on good nodes. One possible explanation could be based on the distribution in time of CPU Speeds on the net. For example, a distribution like the one shown in Figure E may be too erratic to predict by the method of the seed algorithm. Faced with a network of machines showing this kind of behavior, random dispersal is probably the best strategy. On the other hand, if the predominant pattern is like the one shown in Figure G, then it should be possible to have an algorithm to search out good nodes. However, while Figure E looks more erratic than Figure G, it is not clear that it would look so on the time scale in which the digital organism lives and perceives Speed patterns. In addition, the seed algorithm does not attempt to exploit any long term patterns, such as daily cycles.
At this point it appears that it would be worthwhile to gather more data about CPU Speed patterns in time and space on the net, the properties of the TPing sensory system (particularly the latency of data acquisition in relation to the temporal patterns of the data), and the life span, fecundity and migratory patterns of individual organisms. Based on this better understanding of the world in which the digital organisms live and the natural history of the organisms themselves, we could then design and test new seed algorithms, which might be better adapted to this world.
{kind=link}
{kind=link}